从零开始实现一个爬虫。
To eat when you’re hungry, to sleep when you’re tired, to take a break when you’re bored, to work on projects that seem fun and interesting. —— Aaron Swartz
关于如何写爬虫,网上已经有很多资源了,随便搜索一下就可以获得很多教程。跟着那些教程,很快就可以达到爬取豆瓣、微博等网站的水平。利用无头浏览器等技术,可以轻松的爬取网上绝大部分可见的资源。
然而,回想起大一刚开始学习爬虫时候的我,当时我还在使用 Python2 ,时常因为错误的编码而陷入困境,在网上的各种博客里复制来的代码运行倒是能运行,但其实哪一句什么意思都不知道,踩了数不清的坑之后才勉强入门。但如果过去的我能够看到现在网上铺天盖地的爬虫教程,我踩的坑会因此而变少吗?
对我来说,答案是否定的。区别可能是,以前我在 CSDN 上复制 Python2 + urllib 的代码,现在我在知乎专栏复制 Python3 + requests 的代码。
因此,我决定自己写博客来讲解如何写爬虫。考虑到现在我的博客日访问量还是个位数,因此我大概率是写给自己看的。当然这并没有什么关系,就当作是写给大一时候的我自己了。
所需基础
如果可以的话,我肯定是想能让零基础的人也能学会,然而我的能力它不允许啊……
因此,在学习之前,你需要以下前置技能:
- Python 基础
- TCP/IP 基础(稍有了解即可)
- HTML 基础
- JavaScript 基础
你需要以下环境:
- 能够联网的电脑
- Python 3.6 +
- 不需要第三方库
在学习完之后,你应该会获得以下技能:
- 基础的爬虫技能
本系列博客以完成一个完整可用的爬虫框架为目标,读者需要通过框架的代码来了解爬虫。我会尽可能的以渐进的方式编写代码与撰写博客,读者最好能够跟着教程实际敲一下代码,以此来加深理解。
起步
包括 Web 网站、各种小程序、软件等在内,现行的网络世界中产生的大部分流量都是基于 HTTP 协议(HyperText Transfer Protocol ,超文本传输协议)的。因此,为了了解爬虫,我们首先要对 HTTP 协议有个大概的认识。
注意:如果没有特别指明,我们所说的 HTTP 协议均为 RFC2616 中所定义的 HTTP/1.1。HTTP/2 及之后版本的变动很大,且目前还只在小部分范围内被使用,因此此处不考虑这些较新的协议,之后将单独对其进行讲解。
HTTP 基于 TCP 协议——一种可靠的传输协议。因为它偏离了我们要讲解的主题,如果我们不会在这里对其进行详细介绍,可以看一下我之前的几篇博客,了解一下 TCP:
如果你确实没有相关的基础也没关系,你可以用“连接的双方互相(可以同时)向对方发送字符串的协议”来理解 TCP。双方是指客户端方(主动发起连接方)和服务端方(接受连接方),在我们的语境中,就是我们的爬虫和被爬取的网站服务器。
因此,建立在 TCP 基础上的 HTTP,可以简单的理解为用户与网站交换字符串。网站服务器处理请求和浏览器渲染网页,其实都是要先进行解析字符串的。关于 HTTP 协议的字符串格式,同样在 RFC2616 有定义。当然,翻阅全英文的文档是让人有点头疼的,因此我从维基百科上直接复制了一份描述:
- 请求行,例如:
GET /logo.gif HTTP/1.1或状态码行,例如:HTTP/1.1 200 OK- HTTP 头字段
- 空行
- 可选的 HTTP 报文主体数据
请求/状态行和标题必须以
<CR><LF>结尾(即回车后跟一个换行符)。 空行必须只包含<CR><LF>,而不能包含其他空格。
这里的 <CR> <LF> 写在程序里就是 "\r\n" ,打印出来的话表现为两个换行。除了首行外,请求和响应的格式要求是相同的。
请求格式
[请求方法] [Path] [协议版本]
[header 字段]: [header 值]
...
[header 字段]: [header 值]
[数据]
请求样例
GET /index.html HTTP/1.1
Host: example.com
响应格式
[协议版本] [响应状态码] [响应消息]
[header 字段]: [header 值]
...
[header 字段]: [header 值]
[数据]
响应样例
HTTP/1.1 200 OK
Date: Sun, 10 Oct 2010 23:26:07 GMT
Server: Apache/2.2.8 (Ubuntu) mod_ssl/2.2.8 OpenSSL/0.9.8g
Last-Modified: Sun, 26 Sep 2010 22:04:35 GMT
ETag: "45b6-834-49130cc1182c0"
Accept-Ranges: bytes
Content-Length: 13
Connection: close
Content-Type: text/html
Hello world!
编码实现一个基本的请求
先来介绍一个网站: https://httpbin.org ,这是一个用于测试请求的网站,是测试爬虫的最合适的工具之一。比如你访问 https://httpbin.org/get ,它会把你请求的 headers 信息、 url 、参数等信息都返回给你。
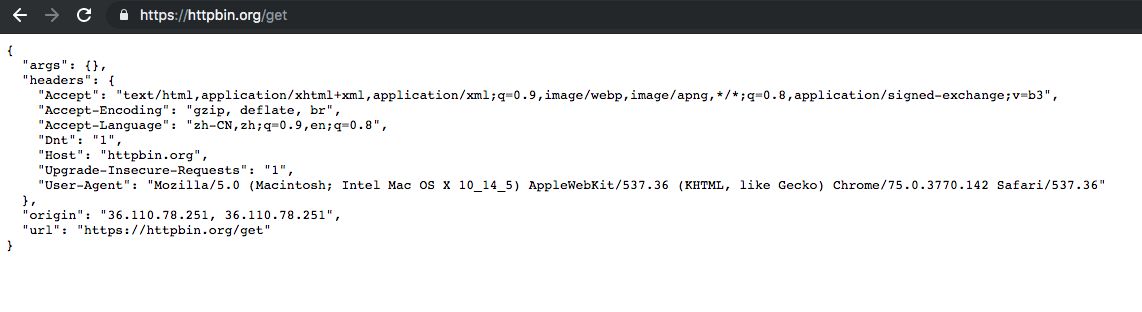
因为 https 需要处理证书加解密,我们现在还无法做到,因此我们使用这个网站的 http 版本 http://httpbin.org ,使用 Python ,请求其 /get 接口。
在 Python 中,创建一个 TCP 连接可以使用 socket 库,这是一个内置库,这里是它的文档。
import socket
sock = socket.socket()
sock.connect(("httpbin.org", 80))
request = "GET /get HTTP/1.0\r\n" + \
"Host: httpbin.org\r\n" + \
"\r\n"
sock.send(request.encode("ascii"))
response = b""
chunk = sock.recv(4096)
while chunk:
response += chunk
chunk = sock.recv(4096)
sock.close()
print(response.decode())
这段代码的意思是,我们构建了一段请求字符串如下:
GET /get HTTP/1.0
Host: httpbin.org
创建了一个与 httpbin.org 的 TCP 连接,并将请求字符串发送给网站服务器。创建了一个 response 的变量来存储服务器发给我们的数据。因为协议中规定了 HTTP 的编码为 ascii ,而 Python3 默认的编码为 Unicode ,因此在发送与接收时我们都需要进行转码。
需要注意的是, sock.recv(4096) 返回的是读取到的服务器给我们发送的数据,如果数据还没有收到, sock.recv 并不会返回空,而是会一直阻塞在这里,等待数据到达。只有当连接已经断开或者连接出错的时候, sock.recv 才会返回一个空字符串。
有的同学可能会发现,我们上面说我们的教程基于 HTTP/1.1 ,这里发送的却是 HTTP/1.0 。这是因为,在 HTTP/1.1 中, HTTP header 中新增了字段 Content-Length ,服务器会在响应数据的 header 中添加这个字段,用于表示响应数据的长度,正常的浏览器应该识别这个字段,并在服务器传输了足够长度的数据后主动关闭连接。
客户端主动关闭连接可以有效的减少服务器 TIME_WAIT 积压的问题,对这个问题有兴趣的同学可以看一下我的博客《TCP 的三次握手与四次挥手》和《TCP 连接的流程与状态转换》。转回我们的教程,我们还不想在现在的代码中添加主动关闭的功能,因此我们直接发送 HTTP/1.0 的请求给服务器,来规避这个问题。
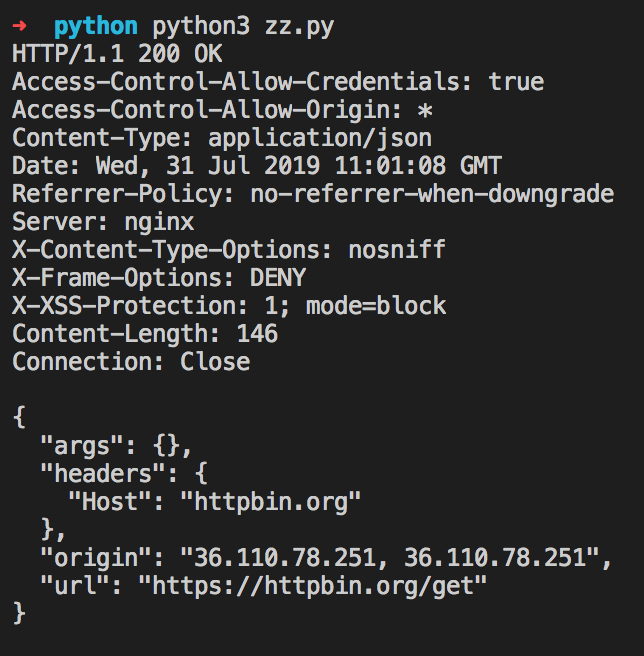
保存代码到本地并执行,我们可以直观的看到其效果:
封装成函数
我们的爬虫当然是不会只访问 httpbin.org 的,我们需要把通用的代码封装起来,供后续调用。
import socket
def fetch(url: str) -> str:
if url.startswith("http://") is False:
raise ValueError("url must start with `http://`")
_tmp = url[7:].split("/", 1)
if len(_tmp) > 1:
host = _tmp[0]
path = "/" + _tmp[1]
else:
host = _tmp[0]
path = "/"
sock = socket.socket()
sock.connect((host, 80))
request = "\r\n".join((f"GET {path} HTTP/1.0", f"Host: {host}", "\r\n"))
sock.send(request.encode("ascii"))
response = b""
chunk = sock.recv(4096)
while chunk:
response += chunk
chunk = sock.recv(4096)
sock.close()
return response.decode()
我们将爬虫通用的逻辑封装成了一个叫 fetch 的函数,这个函数接受一个 url 参数,请求对应的网站并返回其响应。我们可以在其他地方使用这个函数。
将代码保存为 fetch.py ,在同一个目录下打开一个终端( Windows 下可以 PowerShell ),启动 python 并输入以下代码:
>>> from fetch import fetch
>>> resp = fetch('http://httpbin.org/get')
>>> resp
'HTTP/1.1 200 OK\r\nAccess-Control-Allow-Credentials: true\r\nAccess-Control-Allow-Origin: *\r\nContent-Type: application/json\r\nDate: Wed, 31 Jul 2019 12:07:58 GMT\r\nReferrer-Policy: no-referrer-when-downgrade\r\nServer: nginx\r\nX-Content-Type-Options: nosniff\r\nX-Frame-Options: DENY\r\nX-XSS-Protection: 1; mode=block\r\nContent-Length: 146\r\nConnection: Close\r\n\r\n{\n "args": {}, \n "headers": {\n "Host": "httpbin.org"\n }, \n "origin": "36.110.78.251, 36.110.78.251", \n "url": "https://httpbin.org/get"\n}\n'
验证通过,我们的函数已经可以请求网站了!
创建框架
虽然我们的函数已经可以实现请求了,但我们要做的是一个爬虫框架,需要更高的适用性。为了将我们的函数封装成框架,我们首先创建以下的目录结构:
ZeroCrawler
|
|------ ZeroCrawler
| |-------- __init__.py
| |-------- fetch.py
|
|------ tests
|-------- test_fetch.py
文件内容分别如下:
__init__.py
from .fetch import fetch
test_fetch.py
import unittest
from ZeroCrawler import fetch
class TestFetch(unittest.TestCase):
def test_fetch(self):
resp = fetch("http://httpbin.org/get")
self.assertTrue(resp.startswith("HTTP/1.1 200 OK"))
if __name__ == "__main__":
unittest.main()
我们添加了 tests 来测试我们的代码,以保证我们代码的可靠与稳定。现在我们的框架已经有了基本的雏形,在下一章里,我们将会把 ZeroCrawler 改造成一个可以安装使用的库。
总结
这一篇里,我们大概了解了一下爬虫的原理,并且写代码实现了一个最基础的爬虫框架。
本章的所有源代码可以在 GitHub :ZeroCrawler Version 0.0.1 中找到。如果有意见或者建议,可以通过评论或者 GitHub Issues 来告诉我。我们下期再见。